혼자 만들지만 혼자 리뷰하지는 않습니다
BurstPick은 사진작가용 버스트 사진 큐레이션 앱입니다. 연사로 쏟아진 수천 장의 프레임에서 최고의 컷을 골라내는 도구인데, 온디바이스 ML 모델 22개에 39개 언어 지원까지 얹은 macOS 앱을 혼자 만들고 있습니다. 2026년 2월 14일에 첫 커밋을 했고, 이 글을 쓰는 지금 4주 만에 커밋이 3,177개입니다. AI 코딩 에이전트를 쓰면 코드는 이 속도로 쌓입니다.
문제는 코드를 쓰는 속도가 아니라 검증하는 속도였습니다. 1인 개발에는 리뷰어가 없습니다. 내가 놓친 걸 내가 다시 본다고 찾을 수 있을 리가 없어서, 첫 커밋을 올린 바로 그날 .context/reviews/에 첫 리뷰 파일을 만들었습니다. AI에게 페르소나를 주고 코드를 비평하게 한 겁니다. 4주가 지난 지금 그 폴더에는 리뷰 파일이 401개 쌓여 있습니다. 이 글은 그 리뷰 시스템이 어쩌다 이렇게 커졌는지에 대한 기록입니다.
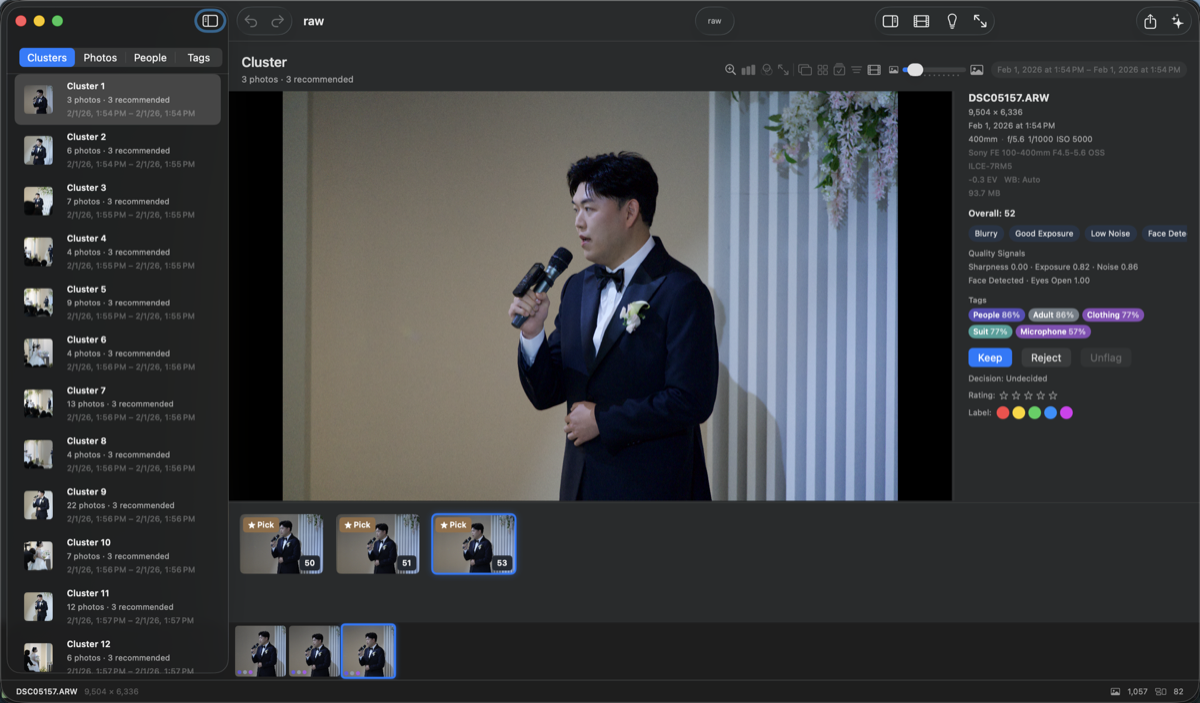
이틀 만에 받은 혹평
첫 커밋 다음 날인 2월 15일, 프로 사진가 페르소나에게 종합 리뷰를 시켰습니다. 판정은 이랬습니다.
“Strong AI foundation, but not usable for professional culling due to critical viewer limitations”
ML 파이프라인은 칭찬받았는데, 도구로서는 실격이라는 겁니다. 점수 매기는 모델이 아무리 좋아도 뷰어가 프로의 속도를 못 따라가면 컬링 도구가 아니라는 거죠. 코드 품질 리뷰였다면 절대 나오지 않았을 지적입니다.
이 리뷰어는 .context/agents/에 있는 마크다운 파일 하나로 정의됩니다. 그냥 “사진가처럼 리뷰해줘”가 아니라, Aperture와 iPhoto와 Picasa가 죽는 걸 지켜본 베테랑으로 설정되어 있습니다. 페르소나 문서에는 “사진 도구의 무덤은 넓다”며 살아남은 도구와 죽은 도구의 목록이 실제로 들어 있고, 그래서 이 리뷰어는 매번 “BurstPick이 2년 뒤 버려지면 내 카탈로그는 어떻게 되나”를 묻습니다. RAW 원본은 절대 건드리지 않고 모든 결정을 XMP 사이드카와 SQLite 카탈로그에 남기는 설계는 상당 부분 이 질문에 답하다가 나왔습니다.
4명이 정착하기까지
첫 주의 리뷰는 임기응변이었습니다. Lightroom 내보내기가 걱정되면 그 리뷰를 시키고, ML 파이프라인이 불안하면 그걸 시키는 식으로요. 2월 22일 Round 12부터 지금의 4인 체제가 자리 잡았습니다. 핫 패스와 동시성을 파는 Systems Performance Engineer, 워크플로우와 데이터 안전을 보는 Pro Photographer, Photo Mechanic 같은 경쟁 도구 대비 포지셔닝을 따지는 Product Marketing, 디자인 토큰과 접근성을 검사하는 UI/UX Designer. 매 라운드 넷이 병렬로 돌고, 통합 리포트로 합쳐서 CRITICAL부터 수정하고, 다음 라운드에서 수정이 진짜 됐는지 검증합니다.
중요한 건 경계입니다. 각자 자기 분야만 봅니다. 마케팅 리뷰어가 코드 품질을 논하기 시작하면 넷이 같은 소리를 하는 값비싼 합창이 되거든요. 이후에도 로스터는 계속 늘어서, 3월 1일에 QA·i18n·접근성 리뷰어가 추가됐고 보안과 코드 품질 도메인까지 붙어서 이번 주 R55 라운드는 7개 도메인이 돌았습니다(평균 8.96/10).
동작 방식 자체는 소박합니다. 페르소나 파일에는 리뷰 전에 반드시 읽어야 하는 컨텍스트 목록이 순서대로 적혀 있고 — ground truth 문서가 항상 첫 번째입니다 — 결과는 .context/reviews/에 기존 번호에서 하나 올린 새 파일로 씁니다. 기존 리뷰를 수정하거나 덮어쓰는 건 금지라서, 폴더 자체가 append-only 히스토리가 됩니다. 점수가 어떻게 움직였는지 보려면 파일을 시간순으로 읽으면 됩니다.
솔직히 그 폴더가 깔끔하지는 않습니다. 초반에는 04-critical-app-review.md처럼 그냥 일련번호였고, 중간부터 103-round12-* 식으로 라운드가 붙었고, 최근에는 r45-*로 또 바뀌었습니다. 같은 번호를 두 파일이 나눠 가진 곳도 있습니다. 네이밍 컨벤션을 두 번 갈아탄 흔적이 그대로 화석처럼 남아 있는 건데, 리뷰 시스템도 결국 코드처럼 리팩터링 부채가 쌓인다는 증거라 지우지 않고 두고 있습니다.
리뷰어들이 같은 소리를 반복하기 시작했다
라운드가 쌓이니 새로운 문제가 생겼습니다. 이미 고친 이슈를 리뷰어가 다시 지적하고, 의도된 패턴을 결함으로 판정하는 겁니다. 리뷰어마다 세션이 독립적이니 당연한 일인데, 같은 반박을 라운드마다 다시 쓰는 건 낭비였습니다. 그래서 3월 5일에 REVIEW-GROUND-TRUTH.md를 만들었고, 모든 리뷰어가 리뷰 전에 이 문서를 강제로 읽습니다.
내용은 세 종류입니다. 먼저 해결된 항목 — 컨트롤러 다섯 개의 unowned 참조를 전부 weak로 바꾼 것, ML 파이프라인이 원본 CGImage를 끝까지 들고 있던 걸 384px 사본으로 교체한 것 같은 수정들이 커밋 날짜와 함께 기록되어 있어서 재론을 막습니다. 다음은 수용한 패턴 — 비핵심 이미지 연산에 깔린 수백 개의 try?는 의도된 에러 처리 컨벤션이고, 확장으로 쪼개져 있지만 합치면 5,800줄쯤 되는 AppState는 MEDIUM 등급 부채로 인정하되 지금은 안 고친다고 못 박았습니다.
마지막으로 스코프 규칙입니다. Windows 버전(WinUI 3와 ONNX Runtime, DirectML로 가는 별도 저장소)은 macOS 리뷰에서 언급 금지입니다. 다른 타임라인으로 가는 다른 프로젝트의 미비를 지적해 봐야 점수만 흐려지니까요.
여기에 점수 규칙을 하나 얹었습니다. 수정이 반영됐으면 점수는 절대 내려가면 안 된다는 단조 비감소 규칙입니다. 이게 없으면 리뷰어가 라운드마다 새 트집으로 점수를 깎아서, 점수 추이가 아무 신호도 못 주게 됩니다.
리뷰에서 수정으로 넘어가는 쪽도 형식이 생겼습니다. 통합 리포트에서 수정 계획을 .context/plans/로 뽑아 라운드 단위로 관리하고, 라운드가 끝나면 아카이브합니다. 3월 10일의 커밋 메시지가 “R50 리뷰 사이클 계획 추가, R49 아카이브”인데, 이쯤 되면 혼자 하는 개발이라기보다 리뷰어 일곱에 플래너까지 딸린 팀의 스크럼 보드에 가깝습니다. 사람이 저 하나뿐일 뿐이죠.
이슈에 가격표 붙이기
리뷰 시스템에서 가장 효과가 좋았던 장치는 심각도 등급이 아니라 달러 비용이었습니다. 사진가 리뷰어가 이슈를 보고할 때 “이걸 안 고치면 사용자가 얼마를 잃는가”를 추정하게 한 겁니다. Lightroom 계층 키워드를 내보내지 못하는 문제(CG-1)는 카탈로그를 옮길 때마다 키워드를 손으로 재구축해야 하니 건당 $200–500. 그리드 뷰가 임베디드 JPEG를 안 쓰는 문제(CG-3)는 Photo Mechanic의 즉각적인 그리드에 비해 10K장 세션당 $130어치의 사진가 시간 손실. “MEDIUM입니다”라는 말로는 안 생기던 우선순위 감각이, 가격표를 붙이는 순간 생깁니다.
16줄짜리 변경을 4명이 보면
3월 8일의 R45 라운드가 이 시스템의 평소 모습을 잘 보여줍니다. 그 라운드의 변경은 파일 2개, 16줄. 하드코딩된 색상을 시맨틱 디자인 토큰으로 바꾸는 게 전부였습니다.
// BeforeText("Ready").foregroundStyle(.green)
// AfterText("Ready").foregroundStyle(currentTheme.proSuccess)이 16줄에 대해 넷은 전혀 다른 이야기를 했습니다. UI/UX 리뷰어는 raw color literal 일곱 개가 proSuccess/proDestructive/proWarning으로, Color.gray.opacity(0.2)가 proTextQuaternary로 정확히 치환된 걸 확인하고 9.4에서 9.5로 점수를 올렸습니다. 퍼포먼스 리뷰어는 토큰 읽기가 구조체 프로퍼티 접근이라 힙 할당도 새 관찰 의존성도 없다며 “성능 임팩트 제로”로 9.2 유지. 사진가 리뷰어는 “폴리시 작업이지 기능 진전이 아니다”라며 8.1에 묶어뒀습니다. CG-1부터 CG-3까지 열린 이슈가 그대로인데 점수를 올릴 이유가 없다는 거죠.
제일 뼈아팠던 건 마케팅 리뷰어였습니다. 9.3을 유지하면서 이렇게 덧붙였거든요.
README가 “수십 개의 온디바이스 ML 모델”이라고 뭉뚱그리는데 실제로는 6개 카테고리에 정확히 22개니까 구체적인 숫자가 더 강한 주장이라는 것, 그리고 점수가 여기서 더 오를 수 없는 이유는 코드가 아니라 서명된 바이너리도, 구매 페이지도, 마케팅 웹사이트도 없기 때문이라는 것. 엔지니어링은 출시급인데 가게가 없다는 지적을 매 라운드 듣고 있습니다.
39개 언어라는 자충수
39개 언어 지원은 AI 번역 덕에 시작하기는 쉬웠습니다. 유지가 문제였죠. 3월 11일에 11개 로케일에서 2,971개의 크로스 언어 오염 번역 — 엉뚱한 언어가 섞여 들어간 문자열 — 을 찾아 제거했고, 다음 날 141개를 더 걷어냈습니다. 같은 날 베트남어에서는 성조 기호가 통째로 빠진 번역 1,266개를 복원했습니다.
“KEEP”이 “GIU”로 적혀 있던 걸 “GIỮ”로 고치는 식인데, 성조 없는 베트남어는 현지 사용자에게 꽤 이상하게 읽힙니다. 3월 1일에 QA·i18n·접근성 리뷰어를 로스터에 추가한 게 이런 것들 때문입니다. 39개 언어를 눈으로 검수하는 건 혼자서는 불가능하고, 오염을 찾는 것도 결국 자동화된 리뷰의 일이 됐습니다.
22개 모델의 무게
BurstPick의 점수 파이프라인에는 화질 평가, 미학 평가, 이미지 임베딩, 얼굴 인식, VLM, 분류까지 6개 카테고리에 22개 모델이 들어 있고, 이 점수들을 조합해 최종 순위를 만듭니다. 화질에는 TOPIQ나 MUSIQ 같은 no-reference IQA 모델, 임베딩에는 DINOv2, 얼굴에는 AdaFace와 EdgeFace 계열, 여기에 SmolVLM과 FastVLM 같은 경량 VLM까지 얹혀 있습니다. 전부 온디바이스라 사진이 기기 밖으로 나가지 않는 대신, 모델 선택의 부담이 사용자에게 넘어옵니다. 그래서 설정 패널에서 모델별 크기·라이선스·정확도 트레이드오프를 보여주고 Speed/Balanced/Quality 프리셋으로 고를 수 있게 했습니다.
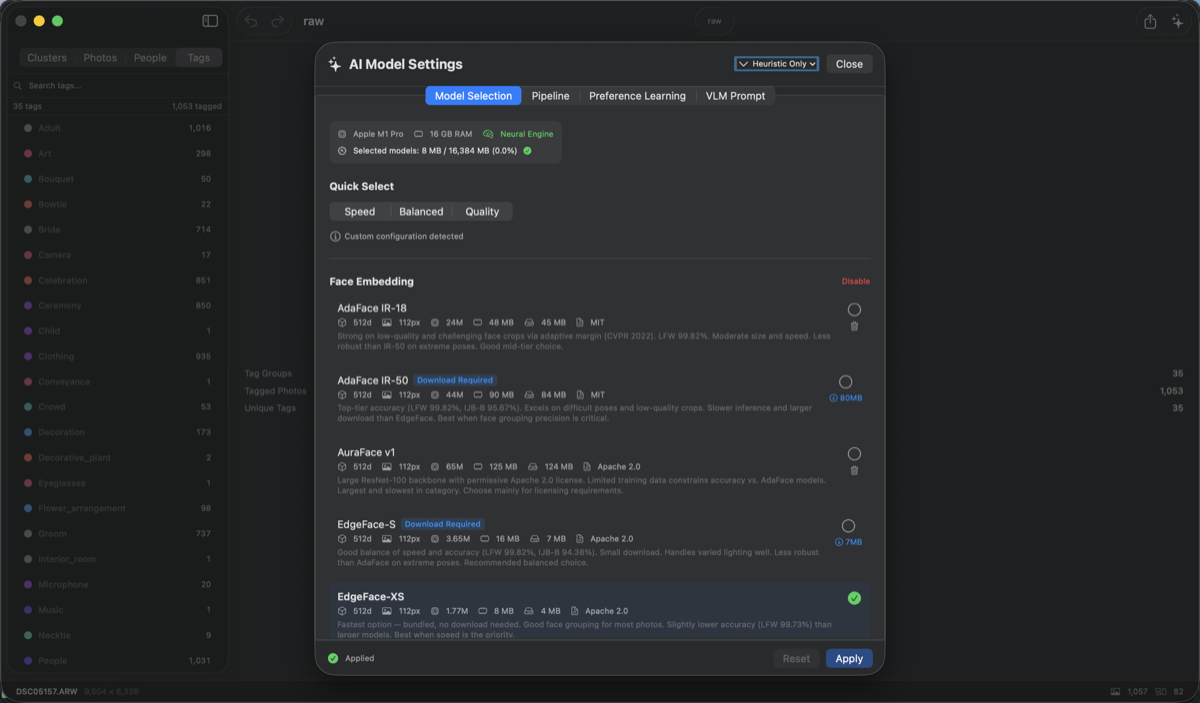
퍼포먼스 리뷰어의 단골 지적이 바로 이 지점의 메모리 압력입니다. 10K장 세션에서 모델을 전부 상주시킬 수는 없으니, 메모리 압력에 반응해 캐시를 비우고 모델을 내리는 코드가 리뷰 라운드를 거치며 계속 다듬어지고 있습니다.
AI 리뷰어가 사람 리뷰어를 대체할 수 있는지는 여전히 모르겠습니다. 다만 첫 커밋 이틀 만에 “이건 프로 컬링에는 못 씁니다”라고 말해주는 존재가 있는 것과 없는 것의 차이는 압니다. 그 말을 해줄 사람이 없어서 혼자 만든 도구가 혼자만 쓰는 도구로 끝나는 경우를 많이 봤으니까요.
지금 리뷰 폴더에는 401개의 리포트가 쌓여 있고, CG-1부터 CG-3까지는 여전히 열려 있습니다. 그리고 마케팅 리뷰어의 말대로, 다음에 고쳐야 하는 건 코드가 아니라 구매 페이지입니다. 리뷰 시스템이 잘 돌아갈수록 남는 숙제는 점점 코드 바깥에 있다는 게, 4주간 401개의 리뷰가 알려준 것 중 제일 예상 밖의 결론이었습니다.
Comments
Loading comments...